JDBC 3.0 Part III - Connection Pooling

Making database connections are expensive in terms of machine resources. In this article, we will examine how a number of connections can be cached in a pool, and then used for accessing the database.
In a world without Connection Pooling, a Connection object encapsulates a real connection to the database. So, when we do a dataSource.getConnection(), what we get back is a real connection. When you are thinking about implementing connection pooling, you have a 'logical' connection (the connection you have in your code), and the 'physical' connection (the object which actually encapsulates the connection to the database). You will see both of these in the diagram below.
The Main Players
The main players in the pooled world are javax.sql.ConnectionPoolDataSource, javax.sql.PooledConnection, and javax.sql.ConnectionEvent.
javax.sql.ConnectionPoolDataSource
This interface serves the same purpose as DataSource (To get an explanation of DataSource, read my April 2004 article at http://www.orafaq.com/articles). ConnectionPoolDataSource returns an instance of PooledConnection. The method signatures are:
public PooledConnection getPooledConnection() throws SQLException; public PooledConnection getPooledConnection(String userName, String password) throws SQLException;
Your JDBC driver will implement this interface.
javax.sql.PooledConnection
This interface encapsulates one of the connections in the pool. It is a factory, which gives us Connection objects via the method:
public Connection getConnection() throws SQLException;
The only difference between this Connection and the one returned by DataSource is that this one is a handle to the PooledConnection. On a similar note, when close() is called, the Connection is not closed, but it is returned to the pool. The connection remains in the pool until time-out or someone else requests one. Consider the diagram:
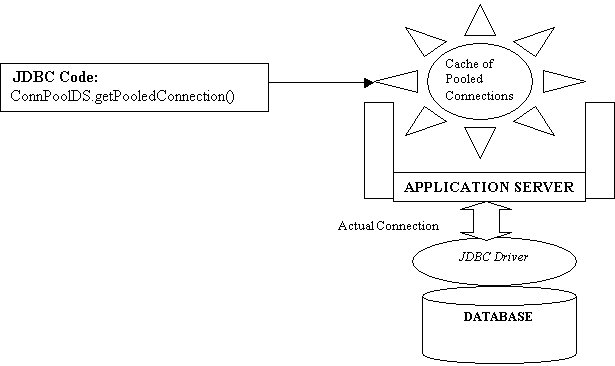
Explanation of the Diagram
As you see in the diagram, your code will ask for a Pooled Connection. The application server implements PooledConnection, and the JDBC driver implements ConnectionPoolDataSource. The application server, which acts as a container for the connection pool, will, in turn, ask for a connection from the driver.
javax.sql.ConnectionEvent
Closing a connection, opening a connection are 'events'. Event-based model is common in the object-oriented paradigm. If an object is notified at the occurrence of an event, that object is known to be the listener. In this case, the listener is the interface ConnectionEventListener. The ConnectionPoolManager implements ConnectionEventListener. It also has to 'register' itself as the listener for the PooledConnection object. The method on PooledConnection is addConnectionEventListener. This part is simple. Having a class implement a listener and registering a listener with a class is common. Other places where listeners are used is HttpSessionBindingListener. ConnectionEventListener has two methods for listening to connection events. These methods map to events. So, basically, there are two events we are looking at: connectionClosed (happens when the Connection object is closed. Note the PooledConnection is still open at this time) and connectionErrorOccured (any hardware error, SQLException, etc.). Note that you, the developer, have no control of the lifecycle of individual PooledConnection's. You can close only the logical connection.
Deploying a Pool
Remember your application server implements the ConnectionPoolDataSource. You will have to check the documentation to find the class. Instantiate the class set the necessary properties and then bind it to a name in JNDI Context. For example:
com.application.server.ConnPoolDataSource cds = new com.application.server.ConnPoolDataSource();
cds.setDatabaseName("myDB");
cds.setServerName("myServer");
Context ctx = new InitialContext();
ctx.bind("jdbc/pooled", cds);
Now that you have your data source named in a JNDI, you can retrieve it in your code and then ask it for a connection. It will return you a Connection. Remember, behind the scenes, there is the PooledConnection.
Other properties of interest that can be set on the datasource are:
InitialPoolSize (the number of connections the pool should hold during creation), minPoolSize (minimum number of connections to be maintained in the pool, 0 means connections will be created on a as-needed basis), maxPoolSize (maximum number of connections the pool should entertain. 0 means there is no limit.), maxIdleTime (idle time of connections in pool, in seconds).
Summary
Connection Pooling gives more scalability and gives faster response times, as connections can be re-used across clients. This means the second client will use the same connection the first client used. Implementation of DataSource is your application server-specific in a three-tiered environment and is JDBC driver-specific in a two-tiered environment. Connection Pooling can be done in both two-tier and three-tier environment. Mr Application Server Administrator usually configures the connection pooling environment, some of the parameters of which are: pool size (how many connections you want in the pool), time-out interval and authentication parameters.
Prepared by Saikat Goswami, Boston, Massachussets, sai_nyc@hotmail.com
- Saikat Goswami's blog
- Log in to post comments
Comments
Hi Saikat,
The article is very good. But, if you have explained with support of some code, it would be more useful.
Dear Saikat, In your
Dear Saikat,
In your tutorial you have written: "The application server implements PooledConnection, and the JDBC driver implements ConnectionPoolDataSource".
And later in the same tutorial wherein deploying a pool it is written as "Remember your application server implements the ConnectionPoolDataSource".
What is this ambiguity?
Ambiguity
I noticed it too, but I believe that the ConnectionPoolDataSource is implemented by each specific driver.
please tell if this gets a connection from pooled conections
import java.sql.*; import oracle.jdbc.pool.*; public class DBCon { public DBCon() { try{ Class.forName ("oracle.jdbc.driver.OracleDriver"); OraclePooledConnection pc=new OraclePooledConnection("jdbc:oracle:thin:@10.10.0.4:1521:glob","eipldba","eiplubq"); Connection con=pc.getConnection(); Statement st=con.createStatement(); ResultSet rs=st.executeQuery("Select airline_code,airline_name,br_code from rd_airline"); System.out.println("Hello D"); while (rs.next()) { System.out.println(rs.getString(1)+" "+rs.getString(2)+" "+rs.getString(3)); } con.close(); } catch(Exception e){System.out.println(e);} } public static void main(String dd[]) { try { new DBCon(); } catch(Exception ee){System.out.println(ee);} } }